케라스를 사용한 인공신경망 소개
자연으로부터 영감을 받은 발명품들(새 -> 비행기, 산우엉 -> 벨크로)처럼 인공신경망도 뇌 구조로부터 영감을 받음
새를 보고 비행기를 만들었지만, 날개를 펄럭일 필요는 없는 것처럼 인공신 경망도 생물학적 뉴런에서 점점 멀어지고 있다.
10장에서는 인공 신경망의 초창기 구조, 다중 퍼셉트론, 케라스를 소개 함

뉴런을 사용한 논리 연산
매컬러와 피츠가 생물학적 뉴런에서 착안한 매우 단순한 신경망 모델을 제안함 (MCP)
McCulloch-Pitts 모델에서 사용한 가설은 다음과 같다.
1. 뉴런은 활성화되거나 혹은 활성화되지 않은 2 가지 상태이다. 즉, 뉴런의 활성화는 all-or-none 프로세스이다.
2. 어떤 뉴런을 흥분되게 (excited) 하려면 2개 이상의 고정된 수의 시냅스가 일정한 시간내에 활성화 (activated) 되어야 한다.
3. 신경 시스템에서 유일하게 의미있는 시간지연 (delay) 은 시냅스에서의 지연 (synaptic delay) 이다.
4. 어떠한 억제적인 (inhibitory) 시냅스는 그 시각의 뉴런의 활성화 (activation) 를 절대적으로 방지한다
5. 신경망의 구조는 시간에 따라 변하지 않는다.
하나 이상의 이진 입력과 이진 출력 하나를 가짐
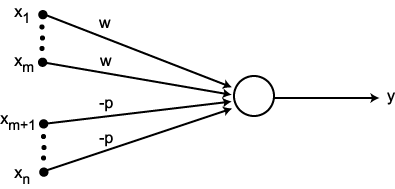
책에서는 입력이 2개 이상 되어야 뉴런이 활성화 된다고 가정함
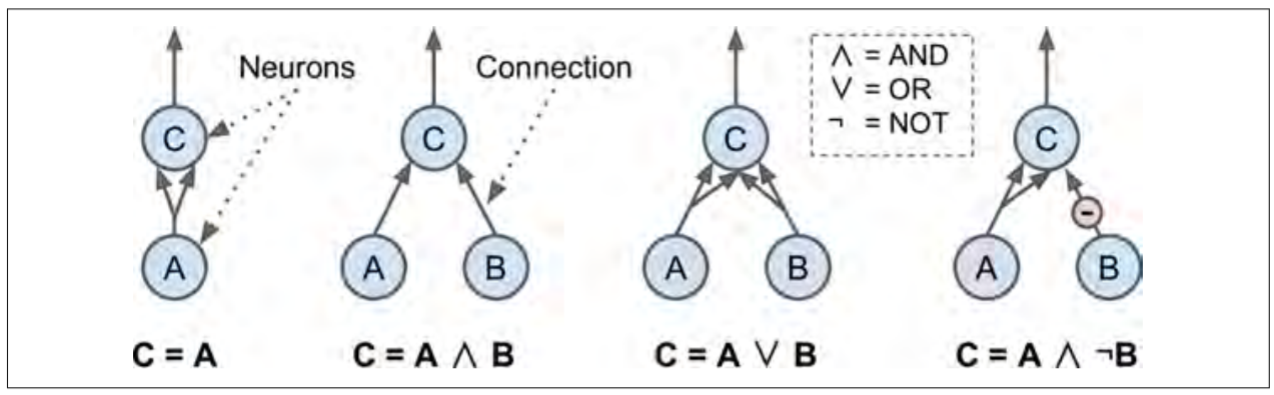
퍼셉트론
퍼셉트론은 가장 간단한 인공 신경망의 구조 중 하나로, 프랑크 로젠블라트가 제안함.
Threshold logic unit, Linear threshold unit (TLU, LTU) 이라고 불리는 조금 다른 인공 뉴런을 기반으로 함
TLU
1. 입력과 가중치를 곱해서 더하고 (z = w1 x1 + w2 x2 + ⋯ + wn xn = wT · x)
2. 계산된 합에 계단 함수를 적용해 결과를 출력함 hw(x) = step (z) = step (wT · x).


하나의 TLU는 간단한 선형 이진 분류에서 사용할 수 있다.
꽃잎의 길이와 너비를 입력으로 붓꽃의 품종을 분류 할 수 있다.
TLU를 훈련한다는것은 최적의 w1,w2,w3을 찾는 것을 의미한다.
퍼셉트론
퍼셉트론은 층이 하나뿐인 TLU로 구성된다.
한층에 있는 모든 뉴런이 이전 층의 모든 뉴런과 연결 되어 있을 때 완전 연결층 또는 밀집 층이라 부른다.
(Fully connected layer, Dense layer)
퍼셉트론의 입력은 입력 뉴련이라 불린다.
입력층에서 입력 뉴런은 어떤 값이든 그냥 통과시키며, 대부분 여기에 편향 특성 뉴런이 더해진다.


학습은 어떻게 할까

- Wi,j 는 i번째 입력 뉴련과 j번째 출력 뉴런 사이를 연결하는 가중치
- xi는 현재 훈련 샘플의 i번재 뉴런의 입력값
- y hat은 현재 훈련 샘플의 j번재 출력 뉴련값
- y j는 현재 훈련 샘플의 출력 뉴런의 타깃값
- r는 learning rate
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # petal length, petal width
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(max_iter=100, tol=-np.infty, random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]])다층 퍼셉트론 역전파

퍼셉트론의 문제점 : 간단한 문제를 해결하지 못함. 예) XOR 논리연산
해결법은 층을 쌓는것
은닉층을 여러개 쌓아올린 인공 신경망을 심층 신경망 DNN 이라고 함
입력층, 은닉층, 출력층 으로 구성
출력에 가까운 층을 상위층, 입력에 가까운 층을 하위층라고 부름

다층 퍼셉트론을 훈련할 방법을 찾기위해 오랫동안 고군 분투했지만, 성공하지 못함
데이비드 루멜하트, 제프리 힌턴, 로날드 윌리엄스가 획기적인 역전파 훈련 알고리즘을 소개
효율적인 기법으로 그래디언트를 자동으로 계산하는 경사 하강법
학습 알고리즘을 살펴보면,
- 하나의 미니배치씩 진행하여 전체 훈련 세트를 처리합니다. 이 과정을 여러번 반복하는데, 각 반복을 에포크라고 부릅니다.
- 각 미니 배치 입력은 첫번째 은닉층으로 보내지고, 정방향 계산을 진행 (이후 역방향 계산을 위해 중간 결과값을 저장)
- 네트워크의 출력 오차 측정
- 각 출력 연결이 오차에 기여하는 정도를 측정, 입력층에 도달할때까지 이전 층의 오차기여 정도를 계산
- 모든 연결 가중치에 대한 오차 그레이디언트 측정
- 오차가 감소하는 방향으로 가중치를 조정


알고리즘을 작 작동시키고자 논문의 저자들은 계단 함수를 시그모이드(로지스틱) 함수 로 바꾸었다.
기존 계단 함수에서는 수평선밖에 없어 계산할 그레이디언트가 없었다.
가장 널리 쓰이는 다른 두개의 활성화 함수는
하이퍼볼릭 탄젠트 함수
RELU 함수
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def relu(z):
return np.maximum(0, z)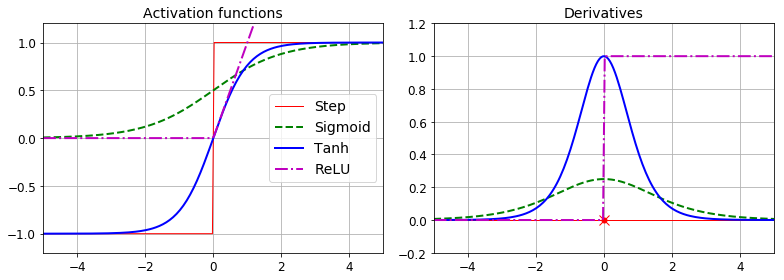
활성함수가 필요한 이유
선형 변환을 여러개 연결해도 선형이 되어버림
f(x) = 2x+3, g(x)=5x-1
f(g(x)) = 2(5x-1)+3
= 10x +1
비선형이 연결된 큰 심층 신경망은 어떤 연속함수도 근사할수있음
회귀를 이용한 다층 퍼셉트론
- 다층 퍼셉트론은 회귀 작업에 사용할 수 있다.
- 값 하나를 예측하는데는 출력 뉴런이 하나 필요
- 다변량 회귀에서는 출력 차원마다 출력 뉴런이 하나씩 필요. (예, 물체 인식 박스 좌표 4개)
분류를 이용한 다층 퍼셉트론
출력은 0과 1사이에 실수, 양성 클래스에 대한 예측 확률
다중 레이블 이진 분류도 쉽게 가능
출력층에는 소프트 맥스 활성화 함수를 사용
모든 예측 확률을 0과 1사이로 만들고 더했을때 1이 되도록 만듬
케라스로 다층 퍼셉트론 구현하기
Notebook 참고
하이퍼 파라미터 튜닝하기
은닉층의 개수
- 이론적으로 뉴런개수가 충분하면 아주 복잡한 함수도 모델링 할 수 있다.
- 하지만, 복잡한 문제에서는 심층 신경망이 얕은 신경망보다 파라메터 효율성이 훨씬 좋다.
- 아래쪽 은닉층은 저수준의 구조를 모델링하고
- 중간 은닉층은 저수준의 구조를 연결해서 중간 수준의 구조를 모델링
- 위쪽 은닉층과 출력층은 중간수준의 구조를 연결해 고수준의 구조를 모델링한다.
- 계층 구조는 새로운 데이터를 일반화 하는 능력도 향상시켜 줌, 예) 전이 학습
은닉층의 뉴런 개수
- 입력층과 출력층의 뉴런개수는 입력과 출력에 형태에 따라 결정됨
- 일반적으로 각층의 뉴런을 점점 줄여서 깔때기처럼 구성
- 저수준의 많은 특성이 고수준의 적은 특성으로 합쳐질 수 있기 때문
- 요즘은 일반적이지 않음 같은 크기를 사용해도 동일하거나 더 나은 성능
- 더 많은 층과 뉴런을 사용하고, 과대적합되기전에 조기종료 규제를 하는것이 더 간단하고 효과적 (스트레치 팬츠)
- 층의 뉴런수보다 층 수를 늘리는것이 이득
학습률 배치 크기 그리고 다른 하이퍼 파라미터
학습률
- 일반적으로 최대 학습률의 절반정도가 최적의 학습률
- 매우 낮은 학습률에서 점진적으로 매우 큰 학습률까지 수백번 반복하여 모델을 훈련하는것
- 11장에서 학습과 관련된 기법을 더 살펴보게 됨
옵티마이저
고전적인 미니배치 경사 하강법보다 더 좋은 옵티마이저를 선택하는것도 중요함.
마찬가지로 11장에서 더 살펴봄
배치 크기
- 많은 연구자들과 기술자들은 GPU 램에 맞는 가장 큰 배치크기를 사용하라 권장하나, 훈련 초기에 종종 불안정하게 훈련됨
- 작은배치가 적은훈련 시간으로 더 좋은 모델을 만들기 때문에 작은 배치를 사용하는게 바람직한다고 주장하는 사람도 있는 반면, 큰 배치크기가 훈련시간을 매우 단축할수 있다고 주장하기도 함
- 11장에서 더 살펴봄
- 훈련이 불안정하거나 최종 성능이 만족스럽지 못하면 작은 배치 크기를 사용해봐라
활성화 함수
일반적으로 ReLU가 모든 은닉층에 좋은 기본 값
출력층의 활성화 함수는 작업에 따라 달라짐
반복 회수
대부분의 경우 반복횟수는 튜닝할 필요가 없음. 대신 조기종료 사용
'프로그래밍 > AI' 카테고리의 다른 글
| msbuild-mcp-server로 C++/C# 코드 빌드 결과를 LLM Agent에 연결하기 (1) | 2025.05.07 |
|---|---|
| 텐서플로를 사용한 사용자 정의 모델과 훈련 (0) | 2021.03.17 |
| Bias and Vairance (0) | 2019.05.05 |
| Double-Dueling-dqn 분석 (0) | 2019.05.05 |
| Ubuntu Tensorflow-gpu 설치 (0) | 2019.05.05 |